Visual Multiplexing
M. Chen, S. Walton, K. Berger, J. Thiyagalingam, B. Duffy, H. Fang, C. Holloway, and A. E. Trefethen
Eurovis 2014
论文中对视觉多通的理解为可正确解码的多可视信息的堆叠方式(“overlaying multiple pieces of visual information while allowing users to recover occluded information”),也就是说把不同视觉通道(颜色、大小、形状等)通过合理的组合方式编码在一起,使得用户能够正确的解码出可视元素所蕴含的信息。这篇论文提出了视觉多通的理论框架并把组合方式分为 10 类。
下图是视觉多通的流程图,左边将某个数据点需要可视表达的的多个信息量记为<_x1, x2, …, xk_>,该数据点通过k个可视映射方法被映射到显示空间的位置p的空间邻域D和时间邻域T,映射结果为<_C1, C2, …, Ck_>(MUX 视觉多路复用过程),用户眼睛观察形成的映射结果,解码信息(视觉多路分离过程)。需要注意的是一个数据点不一定被映射到显示空间中的一个点,它有可能是由位置p周围几个视觉元素组成(空间邻域D)或是一个动态过程组成(时间邻域T)。另外,这个视觉多通的流程对应了信息可视化基本流程中从数据–>可视映射–>用户感知的过程。

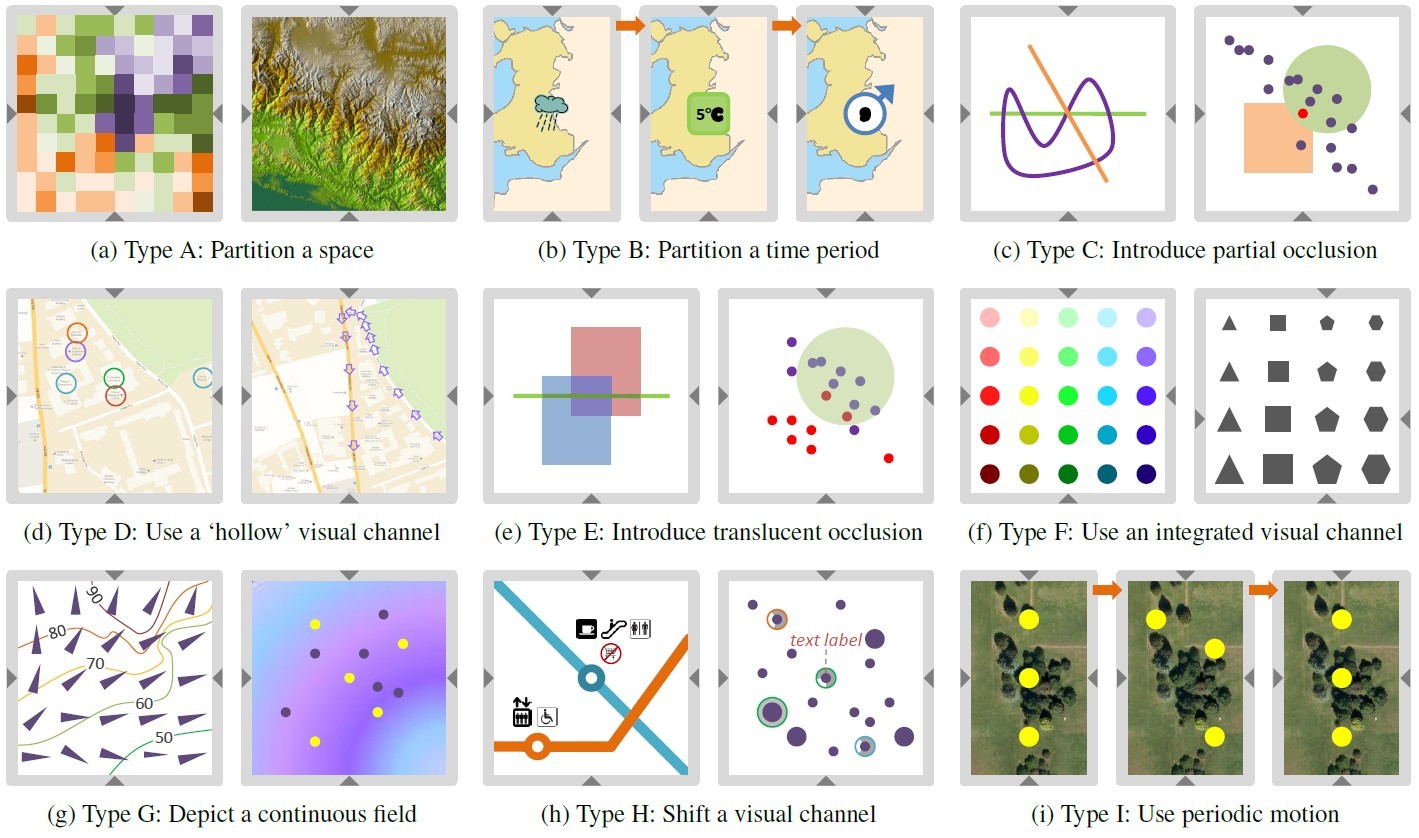
下图为视觉多通的 10 个类型,分别为:
在显示空间上的分割:由空间邻域D的不同可视编码构成的视觉多通
在时间上的分割:即动画,在时间邻域T的不同可视编码构成的视觉多通
部分遮挡:由不透明色块的堆叠构成的视觉多通,有可能因为遮挡造成信息缺失
空心:由空心形状的堆叠构成的视觉多通,空心形状之间的距离可以编码速度等信息
半透明遮挡:由半透明色块的堆叠构成的视觉多通,有可能因为半透明造成的色差引起信息误解
多视觉通道整合:由多个视觉通道的组合(颜色与形状、颜色与大小等)构成的视觉多通
连续场:由向量场、等值线、高度场等连续场构成的视觉多通,结合周围的视觉元素可以判断方向、大小等信息
视觉元素的位移:位置 p 的编码可以位移到p的附近,根据格式塔原则的相近原则依然可以正确解码
周期性动画:由多帧的周期性动画构成的视觉多通
利用先验知识:领域专家可以正确解码的视觉多通方式
利用学习的知识:不需要领域专家,一般用户经过一定训练可以正确解码的视觉多通方式
视觉语言:一般用户经过视觉编码规则的学习可以正确解码的视觉多通方式
作者为整个理论框架的建立提供了四方面的理论依据:类比通信领域的多路复用理论、视觉的(伪)并行处理能力、人的三种记忆形态对视觉感知的影响,以及格式塔原则在分类中的应用。同时,作者列举了可视化领域的多篇论文论证了这 10 类视觉多通方式的应用。
这篇论文提出了视觉多通的理论框架,但视觉多通的分类标准是通过大量应用实例的归纳得到,并没有坚实的的理论依据和量化依据,这是文中提出的未来工作之一。另外,整个理论框架对可视化实践者来说可以作为很好的设计指导,
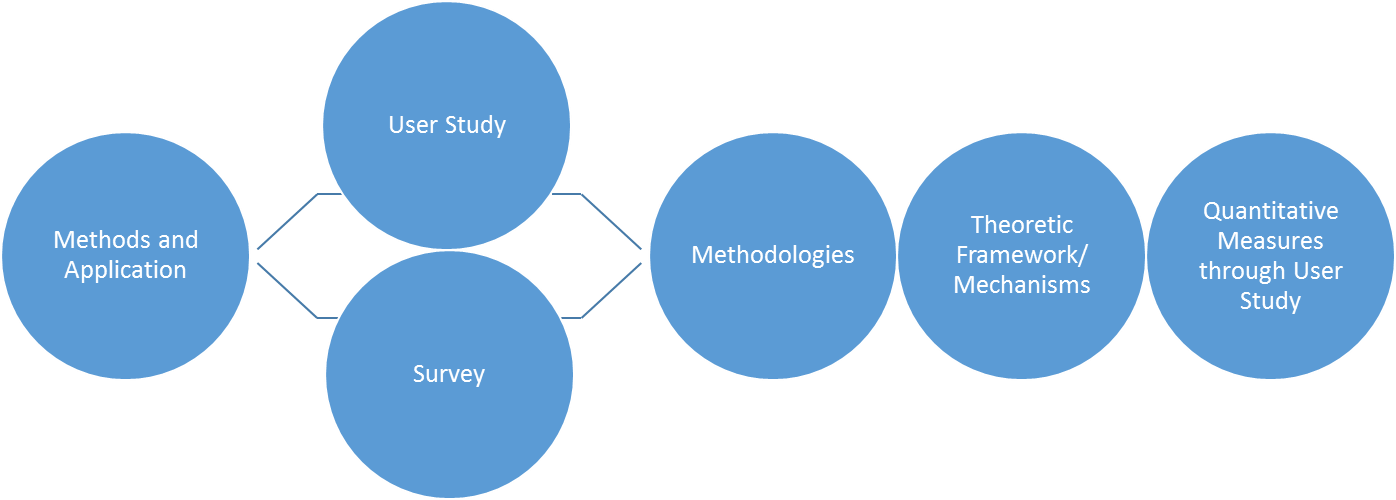
作为题外话,小编总结了可视化理论的发展过程如下图:可视化早期是方法(布局、交互、绘制等)和应用(地理、文本、医学等)的论文居多,然后有了针对方法中的某个点的 user study 和总结方法或应用的综述,在 user study 和综述之上又产生了方法论,方法论之上产生了更加系统的理论框架(如本文的视觉多通框架等),而理论框架又需要更多的量化指标去评价。目前的可视化进入了方法论和理论框架井喷的阶段,但量化指标尚未成熟。但是事无绝对,可视化早期也不乏经典理论框架如可视化过程和可视分析过程,但是目前还没有量化指标去衡量某个可视化作品的可视化完备性(其实也没有可视化完备性的定义)。
✉️ zjuvis@cad.zju.edu.cn